Integrating Agentic RAG with MCP Servers: Technical Implementation Guide
Retrieval-Augmented Generation (RAG) combines a language model with external knowledge retrieval, so the model’s answers are grounded in up-to-date facts rather than just its training data.

In a RAG pipeline, a user query is used to search a knowledge base (often via embeddings in a vector database) and the top relevant documents are “augmented” into the model’s prompt to help generate a factual answer.
This reduces hallucinations and allows domain-specific or private data to be used in responses.
~~~~~~~
Tip: The following are two articles I wrote that talk about:
- Comparing RAG, RAG Fusion, with RAPTOR: Different AI Retrieval-Augmented Implementations
- RAGFlow an Open-Source Retrieval-Augmented Generation (RAG) Engine
~~~~~~~~
However, traditional RAG has limitations: it usually queries a single data source and only performs one retrieval pass, so if the initial results are poor or the query is phrased oddly, the answer will suffer
There’s no built-in mechanism for the system to reason about how to retrieve better information or to use additional tools if needed.
Agentic RAG
Agentic RAG addresses these gaps by introducing an AI agent into the RAG loop. In an agentic RAG system, the retrieval and generation components are orchestrated by an intelligent agent that can plan multi-step queries, use various tools, and adapt its strategy based on the query and intermediate results. In other words, “agentic RAG describes an AI agent-based implementation of RAG” that goes beyond static one-shot retrieval
The agent is typically powered by an LLM and augmented with: 1) Memory (short-term to hold the conversation state, and long-term to remember prior knowledge), 2) Planning/Reasoning abilities (to decide what actions to take, like reformulating a query or choosing a data source), and 3) Tools/Interfaces to external systems (such as search engines, databases, calculators, etc.).
These allow the agent to dynamically decide if and when to retrieve information, which source or API to use, and even to verify or cross-check information before final answer generation.
🔥 Weaviate has an amazing explanation of Agentic RAG.
Categorization of AI Agents in RAG Systems
Agentic RAG systems may include:
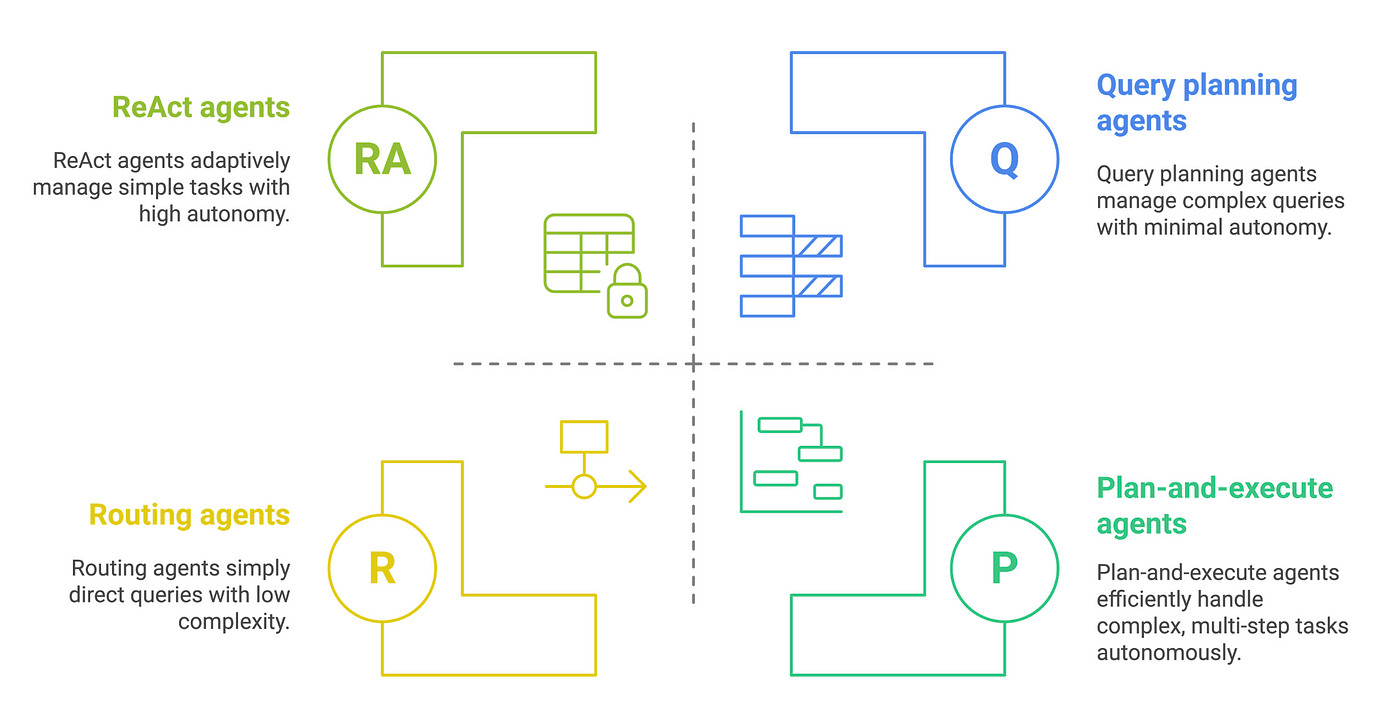
Routing Agents
These agents function as traffic directors in the RAG ecosystem. They analyze incoming user queries and determine which knowledge sources or tools would be most appropriate. In simpler RAG implementations, they select the optimal data source to query for information.
Query Planning Agents
Acting as project managers, these agents break complex queries into manageable subtasks. They:
- Decompose intricate questions into logical steps
- Delegate these subtasks to appropriate agents within the system
- Compile the various responses into a cohesive final answer
This orchestration of multiple AI models represents a sophisticated form of AI coordination.
ReAct Agents
ReAct (Reasoning and Action) agents create and implement step-by-step solutions through:
- Developing logical solution pathways
- Identifying helpful tools for each step
- Adaptively modifying subsequent steps based on intermediate outcomes
This flexibility allows them to adjust their approach as new information emerges.
Plan-and-Execute Agents
These represent an evolution beyond ReAct agents, with capabilities to:
- Execute complete workflows independently without constant supervision
- Reduce operational costs through increased autonomy
- Achieve higher completion rates and quality by comprehensively reasoning through all required steps
Each agent type contributes unique capabilities to create more intelligent, responsive RAG systems.
Actively Engaging with Data
By “actively engaging” with data rather than just retrieving once, agentic RAG systems can produce more accurate and context-aware results. They can pull data from multiple knowledge bases or APIs (flexibility), adapt to different query contexts or user needs (adaptability), and iteratively refine retrieval results for higher quality answers (improved accuracy).
Agents can also perform multi-step reasoning — for example, formulating a better search query or doing a second retrieval if the first attempt wasn’t sufficient.
This means if the user’s question is vague, the agent might break it down or rephrase it to retrieve useful info (a technique known as self-query or query reformulation). Additionally, an agent can incorporate a validation step — checking retrieved facts or filtering out irrelevant snippets — to ensure only reliable information is used
Agentic RAG transforms a passive lookup system into an “adaptive, intelligent problem-solving” pipeline where the LLM can take initiative and use tools to get the best answer.
Introduction to Model Context Protocol (MCP) Servers
As AI agents become more “agentic” and tool-using, a challenge emerges: how to connect the AI to all these external data sources and tools in a consistent, scalable way. This is where the Model Context Protocol (MCP) comes in. MCP is an open standard that standardizes how applications provide context to LLMs. It’s often described as “a USB-C port for AI applications,” creating a universal interface to plug in external data and services. See https://modelcontextprotocol.io/introduction
In essence, MCP defines a common protocol for AI assistants (clients) to communicate with external MCP servers that provide data or actions. An MCP server is a lightweight program exposing specific capabilities (a data source or a tool) through this standardized protocol. For example, one MCP server might provide access to a company’s document repository, another might interface with emails or a calendar, and another could connect to a database (all following the same interaction rules).
Anthropic introduced the concept of MCP back in 2024.
MCP avoids the need for custom integrations for every new data source. Instead of a tangle of one-off connectors, an AI agent can integrate with any number of data sources or tools as long as each provides an MCP-compliant server.
The following diagram shows three progressively more capable ways of connecting a large language model (LLM) to external data or “tools.”
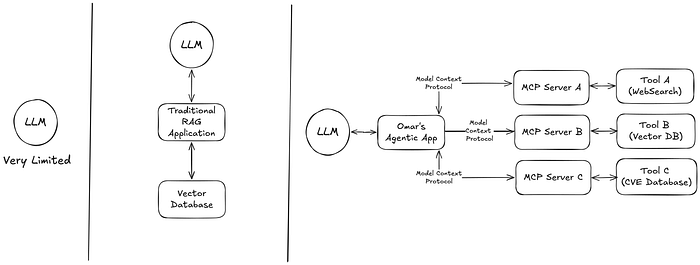
From left to right… LLM by itself (far left). The LLM operates in isolation with no direct connection to outside data sources or applications. It can only answer using the knowledge it was trained on, so it is “very limited” in terms of updating or retrieving new information.
Typical RAG application (middle). Here, the LLM can get context from specific tools or data sources (like a vector database, a custom application, or a web search API). Each tool is integrated separately, so the AI application must “know” how to talk to each one.
LLM using a Model Context Protocol (MCP) server (right). Instead of the LLM connecting to each tool directly, there is a single MCP layer in between. The LLM sends requests to the MCP, and the MCP then routes them to the correct tools (vector DB, custom app, web search, etc.). This standardizes how the LLM gets context or performs actions, making it easier to add or swap out new tools without changing the LLM’s internal logic. It also simplifies the architecture: the LLM only has one main connection (to the MCP), and the MCP manages all other integrations.
This dramatically simplifies scaling up an agent’s capabilities. Developers can “build against a standard protocol” once and then mix-and-match data connectors as needed.
The MCP servers handle the details of connecting to data (files, databases, web APIs, etc.) and present that data in a format the AI model can use as context. Meanwhile, the AI (MCP client/host side) doesn’t have to know the low-level specifics — it just sends standardized requests (like “search documents for X” or “retrieve item Y”) and receives results. This decoupling of AI logic from data source specifics makes the ecosystem more interoperable and context-rich.
MCP and Contextual Memory
One powerful use of MCP servers is to provide extended memory for AI agents. Because LLMs have limited internal context windows, long conversations or large knowledge bases can’t be fully “remembered” by the model itself. MCP servers can manage long-term contextual data. For example, an MCP server might interface with a vector database that stores conversation history embeddings or user-specific information.
The agent can query this server to fetch relevant past facts or store new information for later. In other words, MCP servers can act as the agent’s “brain extensions,” supplying it with memories or knowledge on demand. For instance, a memory-oriented MCP server could store user preferences, past interactions, or domain knowledge and retrieve them when context is needed. As a concrete example, the open-source mem0 tool can serve as an MCP memory server for a coding assistant: it stores things like code snippets, configuration preferences, and documentation, which the AI can pull in later for context.
This kind of persistent, searchable memory greatly enhances an agent’s ability to maintain context across sessions and personalize its responses. In summary, MCP servers enable two-way context exchange. AI agents can both fetch external context (documents, records, past conversations) and push information to external stores — under a secure, standardized protocol.
System Architecture Combining RAG and MCP
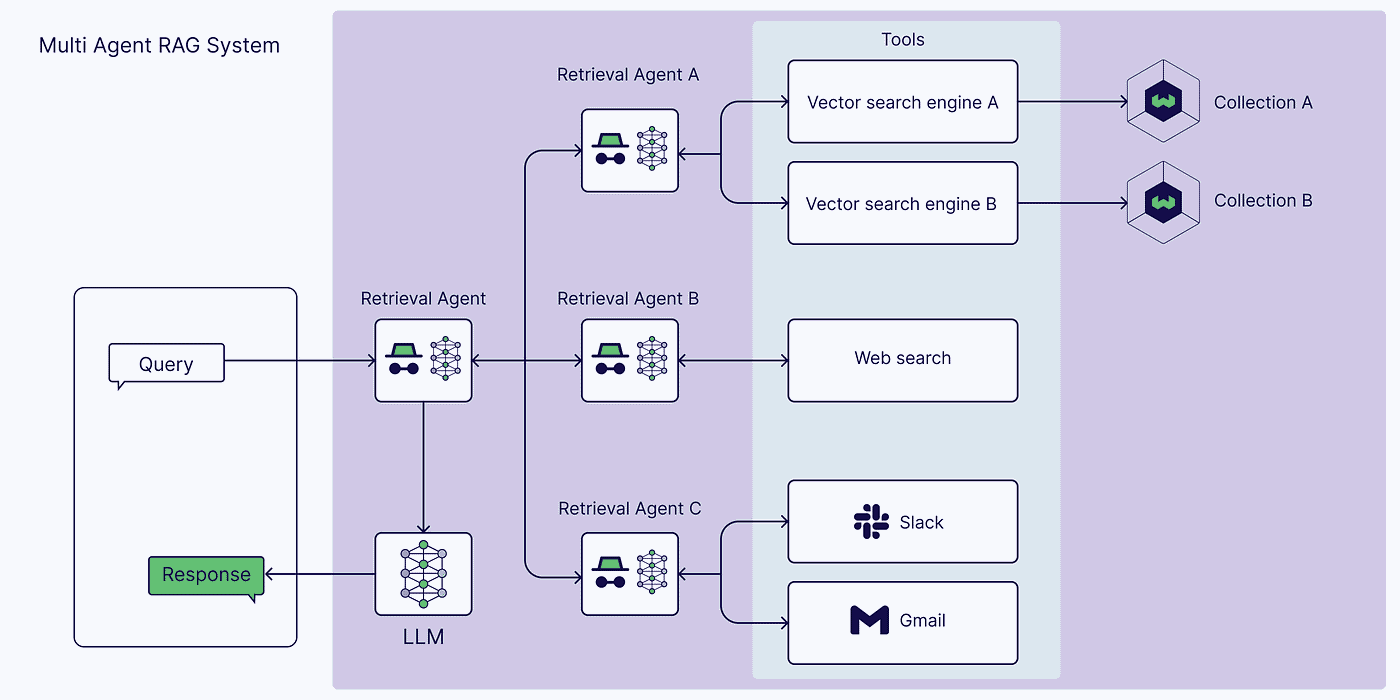
To integrate Agentic RAG with MCP, we need an architecture that allows the AI agent to retrieve knowledge via MCP servers and incorporate it into the generation pipeline. At a high level, the system will include the following components: an Agent (LLM) with planning logic, one or more MCP servers providing access to knowledge sources (and possibly tools), a Vector database or knowledge store (sitting behind an MCP server) for long-term information, and the MCP client interface that connects the agent to those servers. The agent orchestrates the flow: it interprets the user query, decides what data to retrieve, uses the MCP client to query the appropriate server(s), then gets back contextual data which it includes in the LLM prompt to generate a final answer.
Single-agent RAG architecture with an agent acting as a “router” to multiple tools. The agent receives the user query and dynamically selects the appropriate knowledge source or tool: for example, it can query Vector DB A or B (each indexing a different document collection), or call a Calculator, or perform a Web search, depending on what the query requires. The retrieved context is then integrated into the LLM’s input, and the LLM produces a response.
In this combined architecture, the MCP servers essentially serve as the agent’s toolset. Each server might wrap a specific database or service. For instance, you might have:
- an Internal Knowledge Base Server (wrapping a vector database of company documents),
- a Web Search Server (allowing the agent to dispatch web queries),
- a Memory Server (for retrieving conversation context or user profile info),
- and perhaps other utility servers (e.g. a Calculator API, code execution tool, etc.).
The MCP client runs within the AI agent’s process (or the host application) and maintains a connection to each server. This could be a JSON-based RPC over STDIO or HTTP/SSE streams as defined by the MCP spec.
The agent’s logic (which could be implemented via an agent framework or via the LLM’s function-calling abilities) will decide when to invoke a server. For example, if the user asks a question like “What were last quarter’s sales in region X compared to this quarter?”, the agent might:
(1) realize it needs data from a company database,
(2) use the MCP client to send a query to the database MCP server, which in turn runs a query on the database and returns the result.
The agent can then format that result into the prompt or perhaps perform a calculation (maybe via another tool) before generating the answer. All these interactions happen through standardized MCP API calls (e.g. the agent might call a method searchDocuments or getRecord on the server), which appear to the agent as function calls or tool actions.
Data Flow
To illustrate the flow, consider a typical query round-trip in this integrated system:
- User Query Ingestion — The user’s question comes into the Agent (the LLM or a wrapper around it). For example, “Generate a report on open support tickets, and include any recent related customer feedback.”
- Agent Planning — The agent analyzes the request (possibly with a prompt that encourages it to think step-by-step). It identifies that it needs data from multiple sources: support ticket database and customer feedback records. It decides on a plan: first retrieve relevant ticket data, then retrieve feedback, then compose the report.
- MCP Retrieval Actions — Following its plan, the agent (via the MCP client) sends a request to the Ticket Database MCP Server (which might expose a query like
find_tickets(status="open")). The server executes the query on the company’s ticketing system and returns, say, a JSON list of open tickets. Next, the agent sends a request to the Feedback MCP Server (perhaps a vector search over a feedback corpus) with a query related to the tickets (the agent might formulate a specific search like “feedback about product X in last 3 months”). This server returns snippets of relevant customer comments. - Integrating Context — The agent now has raw data: open ticket details and feedback snippets. It incorporates these into the LLM’s context. This can be done by constructing a prompt section like: “Here are the relevant data: [ticket data…]; [feedback excerpts…]. Using this information, answer the query…”. If using a chain-of-thought approach, the agent might also summarize or reformat the data first. In either case, the key is that the retrieved context is passed into the LLM’s input.
- LLM Generation — The LLM (which could be the same model driving the agent’s reasoning, or a separate instance) then produces the answer, e.g. a summary report combining ticket stats with customer sentiment. The agent outputs this to the user.
- Optional Knowledge Storage — After responding, the agent could store some results for future reuse. For instance, it might log the analysis to a knowledge base via an MCP call (e.g. update a “reports” database, or store a summary in a vector memory for the next questions). This ensures that if a follow-up question comes (like “What about last quarter’s comparison you mentioned?”), the agent can recall what it previously computed.
Throughout this process, the necessary APIs include the MCP server interfaces (the functions or endpoints the servers expose, like search queries, create/read operations, etc.) and the LLM’s API (which may support function calling or tool use integration). If using an agent framework, it will call the MCP client’s API under the hood when the agent chooses a tool. From a developer perspective, implementing this architecture means defining the schemas for MCP requests/responses for your servers (often following JSON-RPC schemas for things like SearchRequest, SearchResult, etc.), and ensuring the agent knows how/when to invoke them. The architecture can support both single-agent setups (one agent does it all) and multi-agent setups (where you might have specialized agents). For example, you could have a “Research Agent” that handles web search via MCP, and a “Database Agent” for internal data, coordinated by a master agent. In practice, you might start with a single agent that has multiple MCP tools (as in the diagram above), and later modularize into multiple agents if scaling up (the multi-agent case often just distributes the tool responsibilities among several agent processes or LLMs).
Implementation Steps
Integrating an agentic RAG system with MCP servers involves setting up both the knowledge retrieval pipeline and the plumbing for the MCP connections. Below is a step-by-step guide covering data ingestion, connecting the MCP server, agent integration, and maintenance.
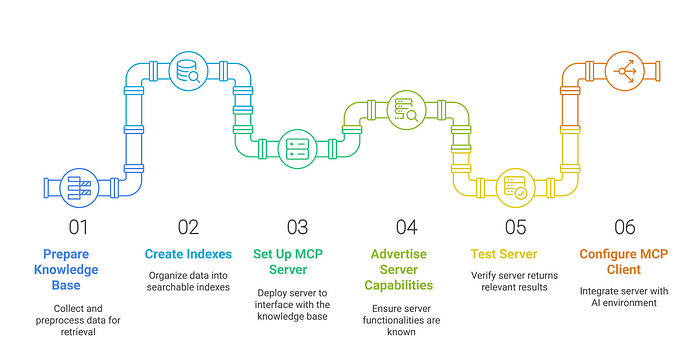
- Prepare the knowledge base and indexes. Start by collecting and preprocessing the data that the AI will need to retrieve from. This might be a set of documents, a database dump, or any textual knowledge. Chunk the data into reasonably sized pieces (for vector search) and embed them using an embedding model to create vector representations. Load these embeddings into a vector database (e.g. FAISS, Weaviate, Pinecone) or another retrieval system
- If you have multiple distinct data sources (e.g. product docs vs. user manuals), you might create separate indexes or collections for each. Also consider what metadata to store with documents (timestamps, categories) to enable filtered or more targeted retrieval queries later. This step ensures your knowledge base is ready for semantic search. (Example: indexing company FAQs into a vector store so they can be queried by similarity to a user’s question.)
- Set Up MCP Server for Retrieval. Deploy an MCP server that interfaces with the above knowledge base. If an official connector exists for your data source, you can use or adapt it; otherwise, you may implement a custom MCP server. For a vector DB, the MCP server would handle requests like “search for X in the docs”. Under the hood it will perform the embedding of the query, run the similarity search in the vector index, and return the top results. Many open-source MCP server examples are available (Anthropic released servers for Google Drive, Slack, SQL databases, etc., which can serve as templates
- Ensure your server advertises its capabilities (in MCP terms, it might list a
resourcesfeature for documents or atoolfor searching) so that the client (agent) knows what functions are available - Test the server independently: e.g. send a sample search request via a JSON-RPC client or the MCP inspector tool to verify it returns relevant documents. If you need long-term memory storage, also set up a Memory MCP server (this could be as simple as another vector store for past dialogues or a key-value store for profile info).
- Configure the MCP Client/Host Environment .integrate the MCP server with your AI agent environment. If you’re using a platform like Claude’s desktop app or an IDE like Cursor, you would register the new MCP server in the application’s settings (for example, in Cursor you add an MCP server by specifying its endpoint URL and type, such as SSE).
In code, if you’re implementing the agent yourself, instantiate an MCP client using an SDK or library provided (there are SDKs for Python, TypeScript, etc. that implement the MCP protocol handshakes.
The client will connect to your MCP server (often on localhost with a specified port if it’s running locally) and perform an initialization handshake. Once connected, the agent can discover what methods or resources the server provides. For example, the server might list a resource like Documents that supports a method search(query). Ensure this connectivity is established at startup, and handle errors (if the server isn’t reachable, the agent should know not to call it).
- Integrate Retrieval Calls in the Agent. Now incorporate the retrieval capability into the agent’s reasoning or prompt-generation process. There are two common integration patterns:
- Using an Agent Framework or Tool-Usage Paradigm: If your LLM supports function calling (OpenAI function calling, etc.) or you’re using a framework like LangChain, you can register the MCP server’s query as a tool function. For example, define a function
search_knowledge(query: str) -> strthat internally calls the MCP client’s search request and returns the results as a string. Provide the LLM with a description of this tool (e.g. “Usesearch_knowledgeto lookup relevant documents from the knowledge base”). At runtime, the LLM can decide to invoke this function when it needs information. The MCP server’s response (e.g. top 3 document excerpts) will be passed back into the LLM, which can then incorporate it into its answer. - Manual Orchestration: Alternatively, you might write custom logic around the LLM. For example, a simple loop where you first call the vector search MCP server with the user query, get results, and then construct a prompt that includes those results before calling the LLM for the final answer. This is a straightforward RAG approach: Answer = LLM(prompt with retrieved context + question). In an agentic setup, you might iterate this: after getting an initial answer, you could examine if the answer seems incomplete and trigger another retrieval with a refined query.
In either case, you need to format the retrieved data appropriately in the prompt. A common practice is to include citations or section headers along with each snippet so the LLM can refer to them. For example: “Document 1 excerpt: … Document 2 excerpt: … Using the above information, answer the question: …”. The agent should also be instructed (via system prompt or few-shot examples) to only use the retrieved info for accuracy. At this stage, make sure the end-to-end query -> MCP retrieval -> LLM answer flow works correctly for basic queries.
Implement Query Expansion or Multi-step Retrieval (Agentic Loop)
To fully leverage agentic capabilities, enable the agent to perform multi-step retrieval when needed. This can be done implicitly by the LLM (the agent can decide, for instance, to call the search tool multiple times). For example, the agent might first retrieve general context, then realize a specific detail is missing and formulate a follow-up query. If using a framework, this is handled by the agent’s reasoning chain (the LLM generates a “Thought: I should search for X” followed by an “Action: search_knowledge” which the system executes, then an observation, etc., as per the ReAct pattern
Ensure that the MCP client can handle consecutive requests efficiently (the servers might remain connected throughout a session). You may need to implement some simple logic like: if the agent’s first retrieval yields no relevant info, have it rephrase the question or broaden the search.
This could involve using the LLM to generate alternative keywords or using fallback tools (e.g. if internal DB had no result, agent switches to a web search MCP server). By allowing this iteration, the system can answer harder queries. Keep an eye on the token usage and set reasonable limits — you might restrict to say 2–3 retrieval calls per user query to avoid infinite loops. In testing, try queries that require the agent to combine information from two sources (ensuring it can call both servers in one session).
Knowledge Update and Storage
Establish how new or updated information will be fed into the system over time (this is crucial for consistency). For static document sets, you might simply rebuild or update the vector index periodically. But if data changes frequently (e.g. an updated policy document or new tickets in a database), consider a pipeline to update the MCP server’s backend. For example, if using a database, the MCP server could query the live data each time (so it’s always up-to-date).
If using a vector store, you might implement an update API on the MCP server — e.g. a method upsert_document(id, content) that re-embeds and stores a new document. Your agent could even call this to “learn” new info during a conversation. Additionally, use the MCP memory server to persist important nuggets from conversations. For instance, after answering a complex question, the agent could store a summary of that Q&A in a long-term memory (via an MCP call) so that next time, it can recall it without recomputation.
Managing knowledge also means setting up a process to validate and clean the knowledge base – remove obsolete info (and maybe have a metadata timestamp to let the agent prefer newer info). By the end of this step, your RAG system should be continuously learning: when the business updates a policy, you add it to the knowledge base (and re-index via MCP); when the agent discovers something new from the user, it notes it down for later.
Finally, rigorously test the integrated system. Try queries of varying complexity and verify that the agent chooses the right tool and provides correct answers. Monitor the latency of MCP calls and the overall round-trip time. If responses seem slow, you might refine the plan (for example, if the agent was doing redundant searches). Tune the number of retrieved documents included in the prompt (sometimes using too many can overwhelm the model — often 3–5 good snippets are better than 10).
Also test edge cases: what if the MCP server is down?
The agent should handle errors gracefully (maybe by responding “I’m sorry, I can’t access the data right now” or trying an alternative route). Once satisfied, deploy the agent in your target environment and monitor its performance over time, ready to patch the knowledge base or add new MCP connectors as new needs arise.
Optimization Techniques
To get the best performance and accuracy from an Agentic RAG + MCP setup, consider the following optimizations:
- Caching and Reuse: Implement caching at multiple levels. Cache the results of common retrieval queries — for example, if many users ask “What is the refund policy?”, you can cache the answer or at least the retrieved document so the agent doesn’t vector-search the same question repeatedly. Also cache embeddings of frequent queries or documents if you generate them on the fly. If the agent tends to request the same resource (e.g. a particular file from an MCP file server) multiple times, the server itself can cache that file’s content in memory. Even partial caching helps — e.g. cache the vector search results for the last N queries during a conversation, so if the user rephrases slightly, you instantly have the context. Just be mindful to invalidate caches when underlying data updates (use document IDs or timestamps to know when to refresh).
- Vector Database Tuning: The vector search is a core part of RAG, so tuning it can improve both speed and relevance. Experiment with embedding models — some models might yield more precise similarity for your domain (domain-specific embeddings can improve retrieval precision). Tune the similarity threshold or top-k for your searches: a smaller
kwill give faster results and less irrelevant data, but too small might miss something; find a sweet spot (often 3–5 documents). Use metadata filters if available – for instance, if the user query has a date, filter documents by date range so you only search relevant slices, which improves both speed and quality. If your vector DB supports hybrid search (combining semantic and keyword), consider enabling that for queries that contain rare keywords (this can catch exact matches that pure embedding search might overlook). Also, maintain your index – periodically remove or archive content that’s no longer needed so it doesn’t clutter results. The goal is to maximize the chance that the top results truly address the query. High precision in retrieval means the LLM has to do less guesswork and can focus on the right info. - Prompt Engineering and Agent Instructions: Craft the prompts that steer the agent and LLM carefully. A well-designed system prompt can significantly improve how the agent uses retrieved knowledge. For example, you might instruct: “If the user’s query seems to require external information, use the knowledge search tool before answering. Only answer using the retrieved information, and if you cannot find an answer, say you don’t know.” This helps reduce hallucination and ensures the agent actually calls the MCP tools when appropriate. Provide examples of using tools: e.g., in the few-shot prompt, show a scenario and the agent’s thought process: User asks a technical question -> Agent thought: “I should search the docs for this API” -> Agent action:
search_docs("API method X usage")-> (MCP returns relevant snippet) -> Agent uses it in answer. Such examples in the prompt teach the model how to behave in the integrated system. Moreover, when formatting retrieved context in the prompt, clearly delineate it (e.g., “Context: ...”) so the model knows that part is reference material. Use special tokens or markdown to distinguish it. This prevents the model from confusing context text with user input or instructions. Another prompt engineering tip is to ask the model to answer step-by-step: you can have the agent first output its reasoning and references (which you capture but don’t show the user) then the final answer. This way, the chain-of-thought can be guided to verify it used the info correctly. Finally, consider instructing the agent to output sources or cite the retrieved docs (if that’s useful for your application), which can improve trust and also allow you to double-check which sources it used. - Efficient Tool Use and Fallbacks: Optimize how the agent chooses and uses tools. If the agent has multiple MCP servers (data sources) available, you can implement a quick query classifier or router before the agent engages fully — for instance, based on keywords, decide which server is most likely relevant and query it first (the agent itself can do this reasoning as well, but a lightweight heuristic can save time). Ensure the MCP servers themselves are optimized (for example, if a server connects to an API, make sure that API calls are efficient or maybe cache API responses if possible). For tools like calculators or code execution, try to batch operations — e.g. if the agent needs to compute multiple things, let it do so in one go if the tool supports it. Also have a failsafe path: if for some reason the agent can’t retrieve the needed info after a couple of tries, it should return a graceful answer rather than hanging. This might be a fallback like “I’m sorry, I couldn’t find the information on that.” Setting a cut-off in the reasoning process avoids excessive token usage and long delays.
- Monitoring and Ongoing Tuning: Treat the deployment as an evolving system. Use monitoring to see how often the agent uses each MCP server, how long each call takes, and the success rate (e.g. did it find something or come back empty). This can highlight where to optimize further. For example, if you notice queries to the “web search” MCP are frequent and slow, you might introduce a small internal knowledge base to cache those answers or upgrade the search MCP to use a faster search API. If the agent rarely uses a certain tool, perhaps its prompt description isn’t clear or it’s not needed — you could remove or refine it. Continuously evaluate the quality of answers; if users report issues, trace back to see if it was a retrieval miss or an LLM error. This feedback loop will guide prompt adjustments, MCP server improvements, or even adding new data sources to fill gaps.
Example Code and Configuration Snippets
To solidify the concepts, here are some simplified code snippets illustrating key parts of the integration. We assume we have an MCP server running for our knowledge base that exposes a search method.
Initializing the MCP client and agent tool
Suppose we use Python and an agent framework for demonstration. First, connect to the MCP server and define a tool function the agent can use:
from mcp import Client # hypothetical MCP client library
from langchain.agents import Tool, initialize_agent
from langchain.llms import OpenAI
# Connect to MCP server (e.g., running on localhost:8080 with JSON-RPC over HTTP)
mcp_client = Client(server_url="http://localhost:8080")
mcp_client.initialize() # perform MCP handshake
# Define a retrieval function that calls the MCP server's search
def search_knowledge(query: str) -> str:
response = mcp_client.request("search", params={"query": query})
# Assume the MCP server returns a dict with 'results' containing text snippets
docs = response.get("results", [])
# Join top docs into a single string (truncate for safety)
return "\n".join(doc["text"] for doc in docs[:3])
# Create a Tool for the agent to use
search_tool = Tool(
name="KnowledgeBaseSearch",
func=search_knowledge,
description="Searches the knowledge base for relevant documents. Input: a query; Output: relevant snippets."
)
# Initialize the language model and agent
llm = OpenAI(model="o3-mini", temperature=0) # or any LLM
agent = initialize_agent([search_tool], llm, agent="zero-shot-react-description")In this snippet, we created an MCP client and wrapped its search call in a function search_knowledge. We then provided that to the agent as a usable tool. The agent (using a ReAct-style Zero-shot agent) will include the KnowledgeBaseSearch tool in its reasoning. Now, when we run the agent, if the prompt or question suggests that external info is needed, it can decide to invoke this tool.
✨ 📚 You can get additional information about LangChain and MCP at https://github.com/langchain-ai/langchain-mcp-adapters
Using the agent to answer a query with RAG
query = "What are the benefits of Agentic RAG over traditional RAG?"
result = agent.run(query)
print(result)When agent.run() is called, internally the LLM might produce something like: “I should search the knowledge base for Agentic RAG benefits” as a thought, then it will call search_knowledge(query). The MCP client sends the search request to the server, retrieves (for example) two snippets from an article on Agentic RAG benefits, and returns them. The agent then gets those snippets and continues the LLM reasoning, eventually producing a final answer that includes the benefits (e.g. flexibility, adaptability, accuracy, etc.) drawn from the retrieved text. The above code is a simplistic illustration – in practice, you’d handle errors and perhaps format the results with citations.
Configuring an MCP server
Let’s say we are setting up a simple filesystem MCP server to allow an agent to read files (this could be used for long-term memory or a local knowledge base of text files). A configuration might look like this (in JSON or YAML) specifying the server’s capabilities:
{
"server": "FileExplorer",
"port": 8090,
"resources": [
{
"name": "Files",
"description": "Access to local text files",
"methods": [
{
"name": "read_file",
"params": {"path": "string"},
"returns": {"content": "string"}
},
{
"name": "search_files",
"params": {"query": "string"},
"returns": {"results": "array"}
}
]
}
],
"permissions": {
"allowed_paths": "/home/agent/docs/"
}
}This hypothetical config declares a FileExplorer MCP server running on port 8090. It has a resource “Files” with two methods: read_file (to get file content) and search_files (perhaps to search text within files). We also specify it can only access files under a certain directory (a security measure). The agent connecting to this server would know, after initialization, that it can call those two methods. For instance, if the user asks “Show me the error logs from yesterday,” the agent might call search_files({"query": "2025-11-14 ERROR"}) via the MCP client, get a list of file hits, then call read_file on the relevant log file. This example shows how MCP servers are configured to expose tools in a standardized way.
PAY ATTENTION TO SECURITY! Don’t give unnecessary access to files! Now, that you saw my disclaimer… Let’s go and see how to store to long-term memory.
Storing to Long-term Memory
If using a vector-store memory, you might directly interact with it in code when new info is to be added. For example:
# After answering a question, store the Q&A in vector memory for future reference
from embeddings import embed_text # hypothetical embedding function
qa_pair = f"Q: {user_question}\nA: {agent_answer}"
vector = embed_text(qa_pair)
memory_db.insert(vector, metadata={"type": "Q&A", "topic": current_topic})If the memory is exposed via MCP, the above could be an MCP server call instead (e.g. mcp_client.request("memory_insert", params={...})). The idea is that the agent can learn over time. Later, when a related question comes, the agent’s retrieval step can search the memory DB to see if a similar Q&A was already done, and use it to answer faster or more consistently.
These code snippets are illustrative — in a real implementation, you’d integrate them according to your specific libraries and infrastructure. But they demonstrate how an agent can call an MCP server like a function, and how we configure and use such servers to extend the agent’s capabilities.
By now, you can see that combining Agentic RAG with MCP servers significantly enhances AI performance by giving the agent both the knowledge it needs (through retrieval) and the contextual awareness of the situation (through memory and data integration). The AI-powered system becomes more autonomous and useful. It can act as a researcher, an assistant, or an analyst that not only has information at its fingertips but also understands when and how to apply it.
